5 Clustering algorithms in real life problems
5.1 Clustering goals:
Simplifying data processing
Data compression
Identification of anomalies (atypical objects)
Building a hierarchy of objects

5.3 Clustering issues:
Fuzzy problem statement
Variety of quality criteria
Prevalence of heuristic approaches
Unknown number of clusters
Dependence of the result on the selected metric
5.4 Most popular Clustering algorithms:
- Statistical clustering
- K-mean
- ISODATA
- FOREL (formal elements)
- Hierarchical/graph clustering
- Density Clustering (DBSCAN/OPTICS)
5.5 K-means method
- Set the number of clusters K
- Select randomly K points as cluster centers
- Determine the nearest cluster center for each point
- Calculate a new cluster center based on the coordinates of its points
- Repeat steps 3-4 until the cluster centers stop changing their location.

Figure 2.3: Example with four clusters:
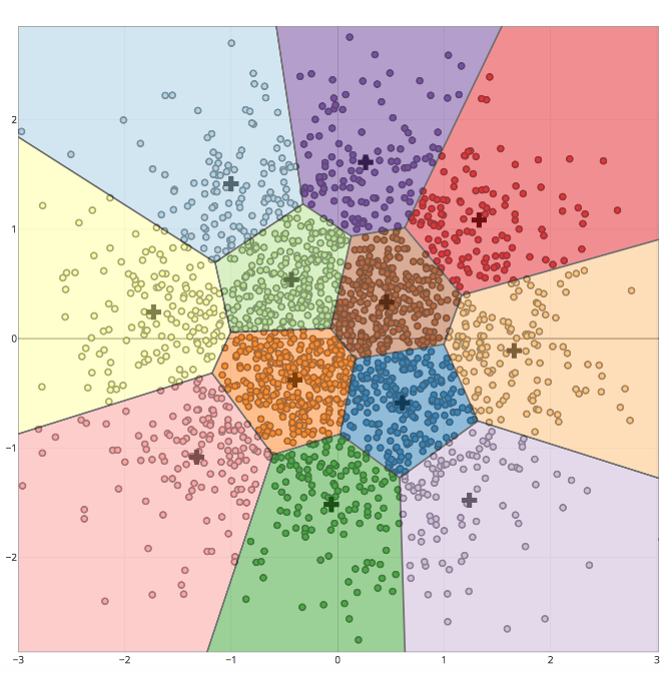
Figure 2.4: All points of the resulting clusters are located inside the cells of the Voronoi diagram for the centers of these clusters:
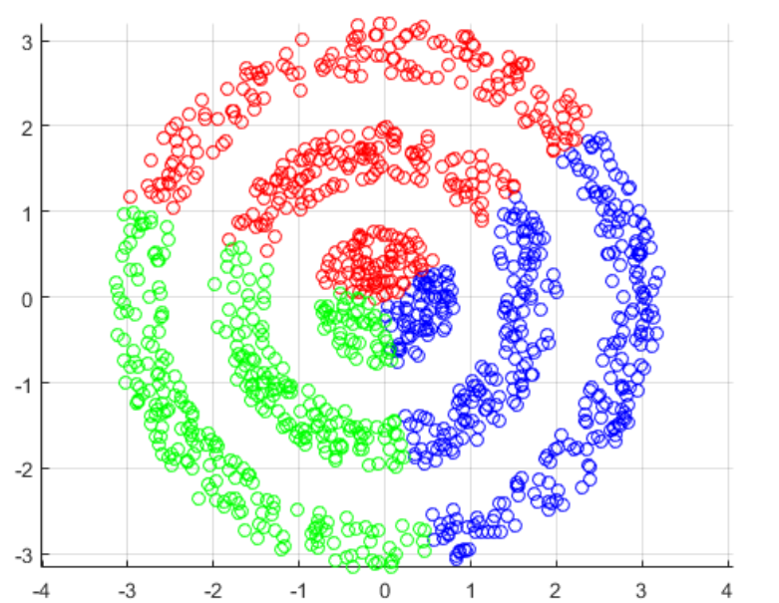
Figure 2.5: The algorithm is good at identifying only spatially separated clusters of convex shape.:
5.6 ISODATA
Iterative Self-Organizing Data Analysis Technique Algorithm
The method starts with one cluster and performs a recursive division of the set along its longest axis until all intra-cluster distances are within a given tolerance. The working algorithm is presented below:

Figure 2.6: ISODATA method
ISODATA method compared to K-means:
- It is not necessary to specify the number of clusters.
- A more robust method for calculating the resulting clusters.
- Also not effective in identifying irregularly shaped clusters.
5.7 Hierarchical clustering
- It is recommended to use Ward’s distance (red line at the picture)
- It makes sense to build several options and choose the best one
- The clustering level is obtained by pruning the tree at a given distance.
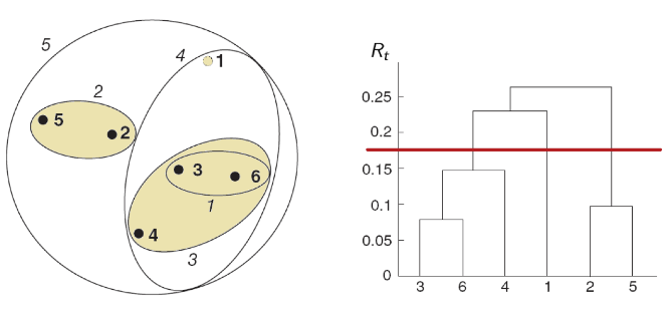
Figure 3.1: Hierarchical method
5.8 DBSCAN
Advantages: 1. The number of clusters is not required. 2. Can find clusters of stable forms. It may even find a cluster that is completely surrounded by, but not connected to, another cluster. 3. Creates noise and is resistant to emissions. 4. Only two parameters required
DISAdvantages: 1. Not completely deterministic: edge points accessible from more than one cluster may be part of any cluster, depending on the order in which the data is processed. 2. Cannot group data sets well where the clusters have different densities.

Figure 3.2: DBSCAN method

Figure 3.3: DBSCAN method
The described clustering methods are far from the only ones, but they are among the most popular. The described clustering methods are far from the only ones, but they are among the most popular. Next, we will look at how these methods are implemented in GEODA.
5.9 GEODA interface
When opening the clustering tools in GeoDA, you can select the clustering method, and then the number of clusters, selection distances, the minimum number of points in the class, etc.
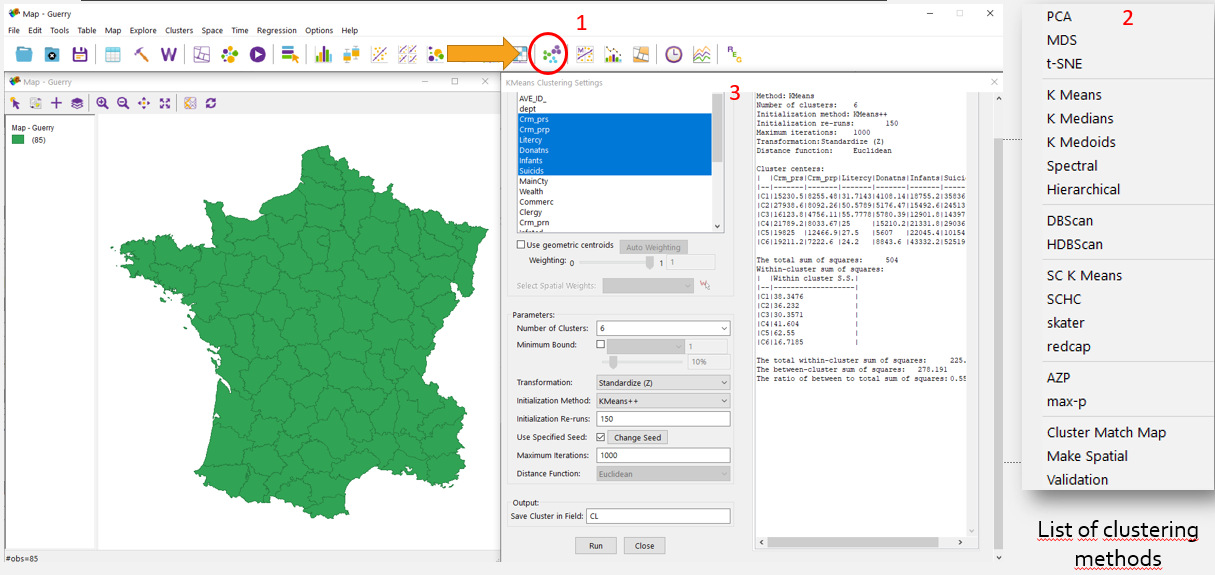
Figure 3.4: 1 - button with clustering tools, 2 - clustering methods? 3 - window with option of clustering
5.10 What Data should I use for clustering?
Clustering can occur on the basis of attribute data, spatial data and their joint significance. At the same time, we can combine attributive and spatial data both in equal importance and giving greater weight to one of the data categories.

Figure 3.5: Variants of how clusters look, depending on the choice of data on which clustering is based.
ATTENTION! Use projected coordinates. NOT geographic coordinates.This is necessary for correct calculation of distances. For example, UTM zone 31 N
We suggest looking at the results of different clustering methods on test data. Test Data Attributes (France, 18th century): 1. Used indicators for example: 2. Population per Crime against persons 3. Population per Crime against property. 4. Percent of military scripts who can read and write. 5. Donations to the poor. 6. Population per illegitimate birth. 7. Population per suicide.
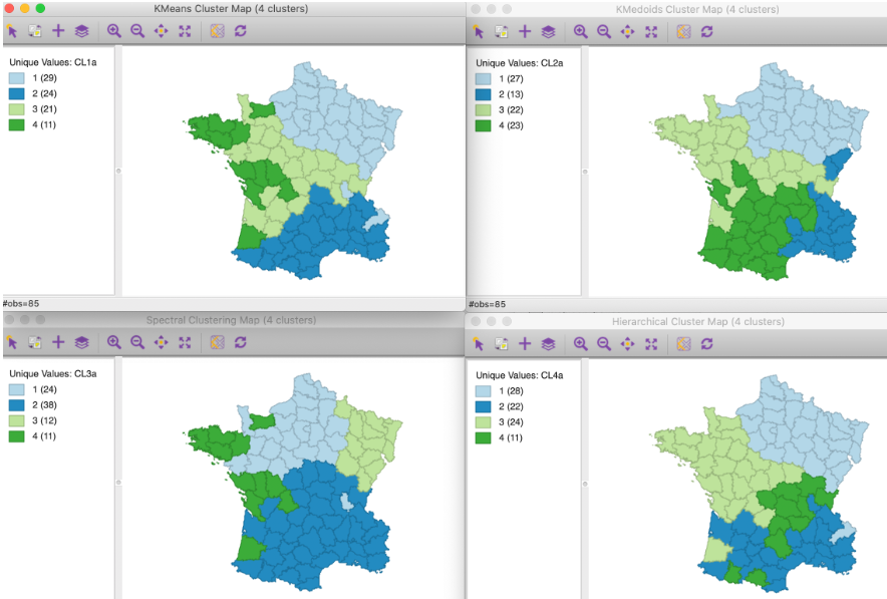
Figure 5.1: 1. K-Means, 2. K-Medoids, 3. Spectral, 4. Hierarchical
HOMETASK: Build a network of electric charging stations for cars in a small town
Electric charging infrastructure is rapidly developing around the world. Imagine that in the small city of your choice there is not a single fast charger for cars. The cost of their construction is high, which means it is necessary to optimally place a small number of fast charging stations. According to the plan, one charging station will be installed per 10,000 people in the city. Exercise: 1. Select a small city (50,000 to 100,000 people). 2. For each house, add a field with the number of apartments or number of residents. 3. Get centroids of residential buildings 4. Group a given set of points. The number of clusters must correspond to the population of the selected city (1 charging station = 1 cluster = 10,000 people). 5. Select the optimal location of charging stations, based on the fact that they should be close to the geometric center of the resulting clusters. 6. Justify the choice of clustering method for this task based on the lecture materials. Draw up a map(s) to justify the optimal location of charging stations, describe the characteristics of the resulting clusters. Send maps and justification for the chosen clustering method to: vitaliy_mapgeo@mail.ru